Understand the General ledger dataset
When importing general ledger transactions from a CSV or Excel file you must assign fields in the file to Caseware fields in the General ledger dataset type you select on import, so that the general ledger data displays correctly in the engagement. This topic details how unique identifiers are autogenerated upon import as well as general ledger data descriptions.
For more information on importing transaction data from CSV files, see Import the client’s transactions from a CSV.
How unique identifiers for general ledger data rows are autogenerated
Knowing how unique identifiers are autogenerated is important if ever data conflicts arise upon data import. See Resolve data import conflicts for more information on how they can happen and what you can do to resolve them.
When you import general ledger data in CSV or Excel files, each data row must be uniquely identifiable. To accomplish this, Cloud creates a unique identifier made up of the values of the fields you assign to the Caseware fields Entry ID (entry_id) and Line Number (line_number) to form a unique identifier for each data row:
{entry_id}-{line_number}
- Where fields from the incoming import file are assigned to Entry ID but not Line Number or vice versa, a unique value is autogenerated for either Entry ID or Line Number, whichever is missing.
- Where fields from the incoming import file are not assigned at all to both Entry ID and Line Number, unique combinations are autogenerated across both of these Caseware fields.
- Where users assign a field to Entry Number but not Entry ID, Entry ID will be autofilled with values from Entry Number.
How general ledger data is stored upon import
General ledger transactions are made up of entries and entry lines. Think of a single data row as an entry line. Every entry line whose Entry ID is the same belongs to the same entry or transaction.
Entry-specific fields
When importing a general ledger dataset, certain fields are consistent across lines within an entry. During an import, these fields will be stored separately, being populated with the values from the first entry line within the entry. The fields include:
-
Entry Number (If Entry ID is also being imported)
-
Posting Date
-
Posting Status
-
Entered By
-
Entered Date
-
Entry Responsible Person
This diagram conceptualizes how values from entry-specific fields are stored upon import. The example below uses Posting Date. The same processing occurs for all the entry-specific fields listed in Entry-specific fields.
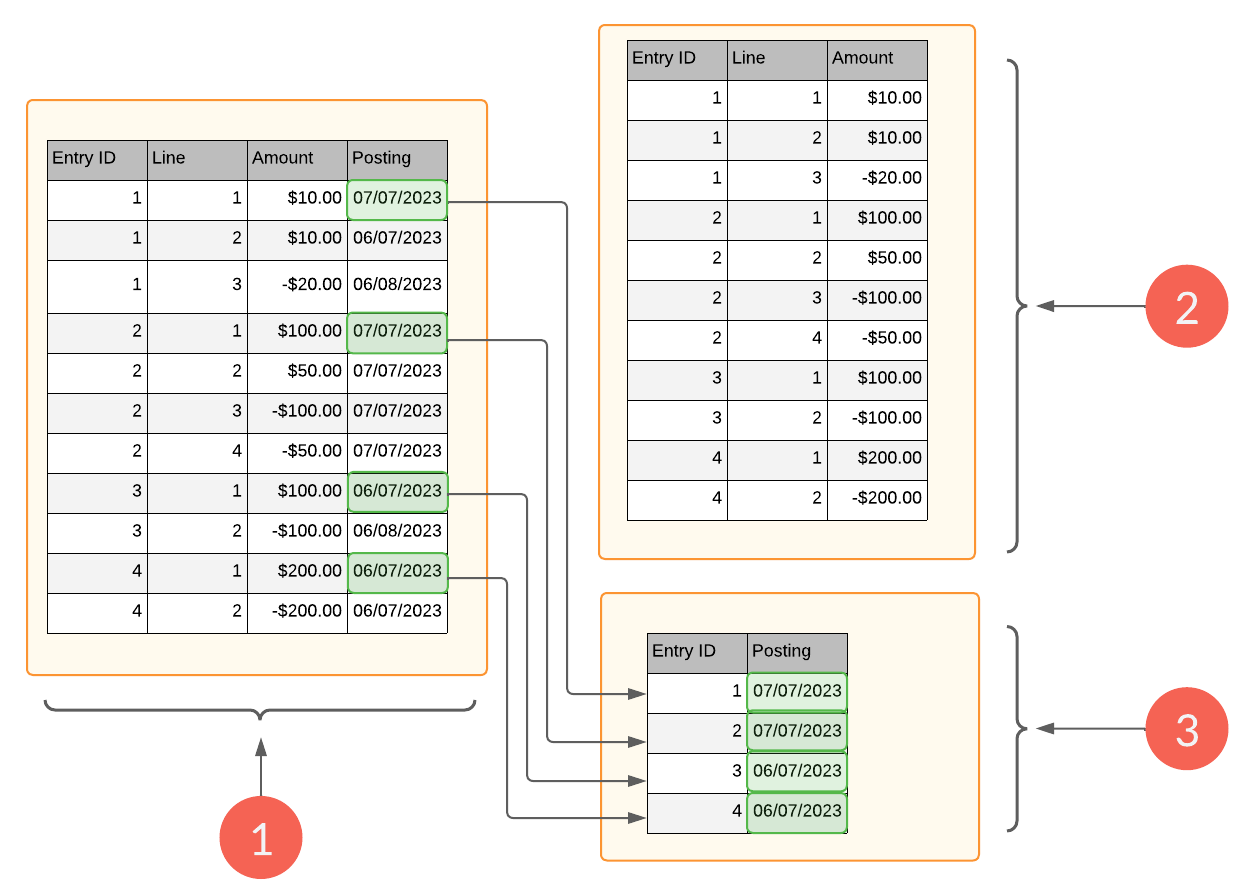
| Element | Description |
|---|---|
| 1 | This general ledger data is about to be imported. Notice that Posting Date is not the same for every line whose Entry ID is the same. All the entry lines whose Entry ID is the same are considered part of the same entry or transaction. Upon import, the first Posting Date encountered for the entry will be stored. The remaining values for Posting Date will be ignored. Those values that will be stored upon import are shaded in green |
| 2 | Here is a simplified example of the Entry Lines table for the General ledger dataset. It stores the primary key for each entry line in addition to any entry-line-specific fields, that is, all the fields in the General ledger dataset less the entry-specific fields listed in Entry-specific fields. |
| 3 | Here is a simplified example of the Entry table for the General ledger dataset. Notice the Posting Date values that are stored. |
General ledger dataset described
See the links below for field descriptions in the General ledger dataset type.